
这个Python脚本可以通过一些排列,来找到未注册的域名。
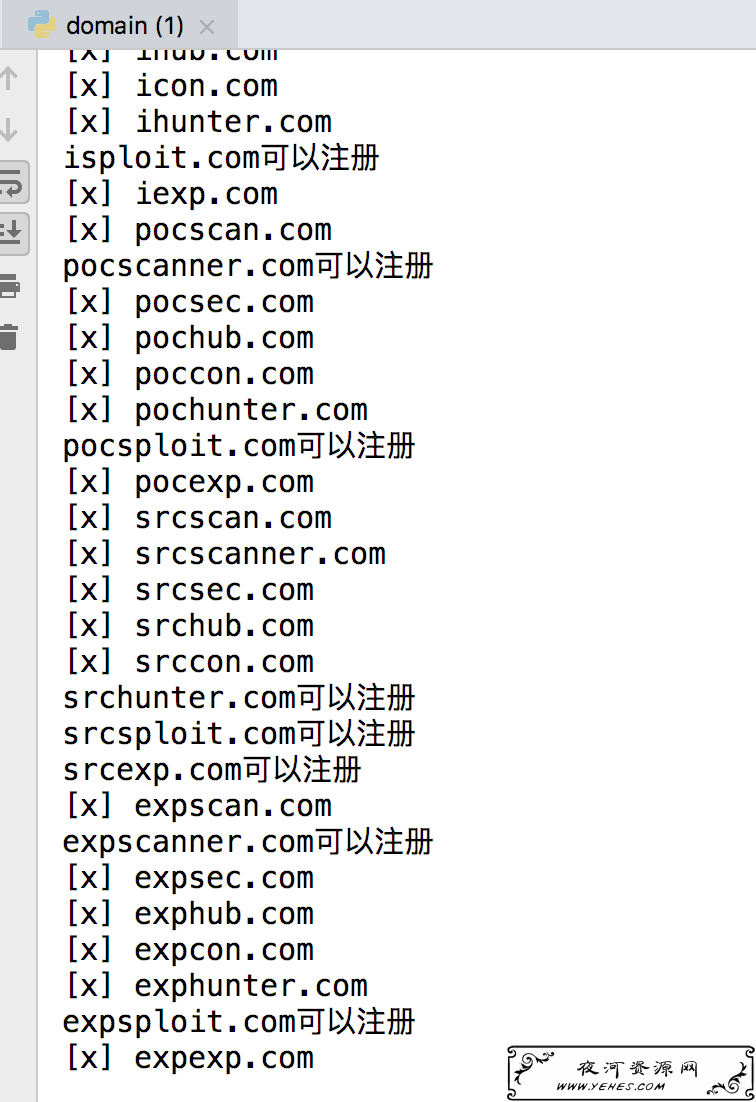
脚本如下
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # @Time : 2019/10/21 3:46 PM # @Author : w8ay # @File : domain.py.py import requests from bs4 import BeautifulSoup import time from itertools import combinations, permutations # 查询是否注册 def check(domain): url = "http://panda.www.net.cn/cgi-bin/check.cgi?area_domain=%s" % domain html = requests.get(url) bsj = BeautifulSoup(html.text, "lxml") onum = bsj.find("original") if onum != None: num = onum.get_text()[:3] if num == '210': print("%s可以注册" % domain) elif num == "213": print("查询超时,请重新查询") elif num == "211": print("[x] %s" % domain) elif num == "212": print(f"{domain} 无效域名") else: print(html.text) print("出现未知问题") return num else: print("让我哭一会,ip可能被封了") return None def search(name, suffix): domain = name '.' suffix num = check(domain) if num != None: if num == '210': return domain return False if __name__ == '__main__': namepart = ['micro', 'hacking', 'scan'] qians = ['micro', 'hack', 'sec', 'vul', 'vuln', 'pwn', 'bug', 'i', 'poc','src','exp'] hous = ['scan', 'scanner', 'sec', 'hub','con','hunter','sploit','exp'] suffixes = ['com'] domains = [] for suffix in suffixes: # names = permutations(namepart, 2) names = [] for qian in qians: for hou in hous: names.append(qian hou) for name in names: domains.append((name, suffix)) for domain in domains: oklist = search(domain[0], domain[1]) time.sleep(0.1)
夜河资源网提供的所有内容仅供学习与交流。通过使用本站内容随之而来的风险以及法律责任与本站无关,所承担的法律责任由使用者承担。
一、如果您发现本站侵害了相关版权,请附上本站侵权链接和您的版权证明一并发送至邮箱:yehes#qq.com(#替换为@)我们将会在五天内处理并断开该文章下载地址。
二、本站所有资源来自互联网整理收集,全部内容采用撰写共用版权协议,要求署名、非商业用途和相同方式共享,如转载请也遵循撰写共用协议。
三、根据署名-非商业性使用-相同方式共享 (by-nc-sa) 许可协议规定,只要他人在以原作品为基础创作的新作品上适用同一类型的许可协议,并且在新作品发布的显著位置,注明原作者的姓名、来源及其采用的知识共享协议,与该作品在本网站的原发地址建立链接,他人就可基于非商业目的对原作品重新编排、修改、节选或者本人的作品为基础进行创作和发布。
四、基于原作品创作的所有新作品都要适用同一类型的许可协议,因此适用该项协议, 对任何以他人原作为基础创作的作品自然同样都不得商业性用途。
五、根据二〇〇二年一月一日《计算机软件保护条例》规定:为了学习和研究软件内含的设计思想和原理,通过安装、显示、传输或者存储软件等方式使用软件的,可不经软件著作权人许可,无需向其支付报酬!
六、鉴此,也望大家按此说明转载和分享资源!本站提供的所有信息、教程、软件版权归原公司所有,仅供日常使用,不得用于任何商业用途,下载试用后请24小时内删除,因下载本站资源造成的损失,全部由使用者本人承担!
一、如果您发现本站侵害了相关版权,请附上本站侵权链接和您的版权证明一并发送至邮箱:yehes#qq.com(#替换为@)我们将会在五天内处理并断开该文章下载地址。
二、本站所有资源来自互联网整理收集,全部内容采用撰写共用版权协议,要求署名、非商业用途和相同方式共享,如转载请也遵循撰写共用协议。
三、根据署名-非商业性使用-相同方式共享 (by-nc-sa) 许可协议规定,只要他人在以原作品为基础创作的新作品上适用同一类型的许可协议,并且在新作品发布的显著位置,注明原作者的姓名、来源及其采用的知识共享协议,与该作品在本网站的原发地址建立链接,他人就可基于非商业目的对原作品重新编排、修改、节选或者本人的作品为基础进行创作和发布。
四、基于原作品创作的所有新作品都要适用同一类型的许可协议,因此适用该项协议, 对任何以他人原作为基础创作的作品自然同样都不得商业性用途。
五、根据二〇〇二年一月一日《计算机软件保护条例》规定:为了学习和研究软件内含的设计思想和原理,通过安装、显示、传输或者存储软件等方式使用软件的,可不经软件著作权人许可,无需向其支付报酬!
六、鉴此,也望大家按此说明转载和分享资源!本站提供的所有信息、教程、软件版权归原公司所有,仅供日常使用,不得用于任何商业用途,下载试用后请24小时内删除,因下载本站资源造成的损失,全部由使用者本人承担!



