
大家有时候可能会需要从网页上抓取一些信息,而抓取信息的过程有时会非常繁琐。如果数据量较大,则只能编程实现。今天我们来手把手地介绍一下怎样使用Beautiful Soup库编写一个最简单的爬虫。
本文作者为香菇肥牛,本文链接为https://qing.su/article/140.html, 转载需经过作者允许且需注明原文链接,谢谢。
我们先来介绍一下Beautiful Soup. 作为一个Python库,Beautiful Soup可以解析HTML和XML,生成树状结构,从而让我们方便地提取需要的信息。
本文我们将以58同城网为例,试图从58同城上获取杭州二手笔记本电脑的相关发布信息。比如,我们希望抓取http://hz.58.com/bijiben/0/pve_9292_1001_2000/这个链接里面所有的二手笔记本电脑发布信息。
1, 安装Python和Beautiful Soup
我们使用Miniconda安装Python3.
|
1
2 |
curl -OL https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh |
Beautiful Soup可以通过PIP安装。我们接着安装PIP.
|
1
2 3 |
apt-get update && apt-get upgrade
apt-get install python3-pip pip3 install –upgrade pip |
最后,我们安装Beautiful Soup及其依赖环境。
|
1
|
pip3 install beautifulsoup4 tinydb urllib3 xlsxwriter lxml
|
2, 分析语段
我们需要了解目标,才能够有针对性地编写程序。我们查看上述网页的源代码,找到其中任意一条出售信息所在的语段块,比如下面这个。
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
<tr logr=”p_1_56550766841365_34960650200492_0_sortid:587929385@ses:yellowclickrank@npos:6@pos:11″ _pos=”0″ sortid=”587929385″>
<td class=”img”> <a href=”http://hz.58.com/bijibendiannao/34960650200492x.shtml?psid=109832630201214014018558150&entinfo=34960650200492_p&slot=-1″ target=”_blank” > <img lazy_src=”http://pic4.58cdn.com.cn/mobile/small/n_v2c2cd317544bb427785596780cee884bf.jpg” src=”//img.58cdn.com.cn/n/images/list/noimg.gif” alt=”九成华硕笔记本出售”/> </a> </td> <!– Written by 香菇肥牛, Link to Post: https://qing.su/article/140.html –> <td class=”t”> <a href=”http://hz.58.com/bijibendiannao/34960650200492x.shtml?psid=109832630201214014018558150&entinfo=34960650200492_p&slot=-1″ target=”_blank” class=”t” > 九成华硕笔记本出售</a> <span class=”ico area”></span><span title=”” class=”ico ntu”>[2图]</span><i class=”clear”></i> 本人出售个人二手笔记本,华硕笔记本有意者联系<i class=”clear”></i> <span class=”fl”><a class=”c_666″ href=”/yuhang/bijiben/”>余杭</a><span> – </span><a class=”c_666″ href=”/qiaosi/bijiben/”>乔司 / </a></span> <i class=”clear”></i> </td> <td class=”tc”> <b class=’pri’>1800</b> 元 </td> <td class=”tc”></td> </tr> |
按照HTML标签的承继关系,我们展现出了相应的缩进,这点在后面的语段分析和爬虫编写中非常重要。观察语段,我们发现这条出售信息的所有元素包含在一个tr标签中,分为四个td标签,类名分别为img, t, tc, tc. 我们需要精准地定位到每一条信息,那么重复出现的类名为tc的两个td标签就不适合用来定位,而只出现了一次的类名为img或者是t的td标签就比较适合用来定位。
类似地,我们也可以通过含有类名t的a标签 a href=”…” class=”t” 来定位。
可以使用Beautiful Soup中的find_all()方法来找到所有满足条件的标签。
|
1
|
results = soup.find_all(“a”, class_=”t”);
|
注意,由于class是Python保留字,所以我们用类名来定位的时候需要将”class”改成”class_.” 定位到了一条信息所在的语段块之后,我们就可以获取对应的信息了。假设我们需要获取下面这几个信息:出售的商品的编号,商品的标题,商品链接,图片链接,以及出售价格。
分析语段可以发现,商品链接直接包含在了我们用来定位的a标签里面,而商品编号也可以直接通过这个链接来截取。我们以records字典来储存需要获取的信息。如果find_all()后所有的结果储存在results列中,且用元素result遍历列,那么下面的方法提取了对应的商品链接和商品编号。
|
1
2 |
records[‘webLink’] = result[‘href’];
records[‘productID’] = result[‘href’][32:51]; |
商品的标题包含在了这个a标签的封装之内,是标签a封装的text. 对于标签封装的text, 可以通过”.string”属性来提取。
|
1
|
records[‘productTitle’] = result.string.strip();
|
我们再来看价格。可以发现,价格在b标签的封装之内,问题是这个b标签距离我们定位用的a标签有点远。再仔细研究标签之间的层级关系,我们发现,这个b标签的上级标签”td class = ‘tc’”是和我们定位用的a标签的上级标签”td class = ‘t’”并列的。这就给我们提供了途径tag “a” —> tag “td” —> next tag “td” —> tag “b”.
从一个标签转移到父级标签,需要使用”.parent”属性。而转移到并列的下一个标签,需要使用”.next_sibling”属性。通常情况下,需要两个”.next_sibling”联用。因此,配合刚才说过的.string, 我们可以提取商品价格了。
|
1
|
records[‘productPrice’] = result.parent.next_sibling.next_sibling.b.string.strip();
|
同样的,图片链接的上上级标签是和我们定位用的a标签的上级标签并列的,且在其之前出现。我们使用”.previous_sibling”属性将操作对象转移至上一个并列标签,通常需要两个”.previous_sibling”联用。
|
1
|
records[‘imgLink’] = result.parent.previous_sibling.previous_sibling.a.img[‘lazy_src’];
|
这样,我们获取了全部需要的信息,可以开始写爬虫了。
3, 翻页
我们再考虑翻页的问题。
上面那条链接里面一共有30条左右的商品出售,如果这个爬虫只能爬取一页的信息,那么对于我们是意义不大的。我们需要它爬取所有页面的信息。因此,让Beautiful Soup正确地找到下一页的地址并翻页显得尤为重要。
审查元素后可以发现,翻页部分的HTML代码是这样的:
于是,我们可以按照上一节的方法,用Beautiful Soup定位class=”next”的”a”标签,读取href字段的内容,从而找到下一页的链接。
|
1
|
nextLink = ‘http://hz.58.com/’ + soup.find(“a”, class_=”next”)[‘href’];
|
其中,find()方法将返回Beautiful Soup找到的第一个对象.
然后将nextLink产生的新链接提交给Beautiful Soup进行下一页的爬取,并进行分析。
4, 其他
至此,关键部分的编写已经完成。我们仅需将这些内容封装在函数中,并编写主函数即可。爬取的结果这里将写入xlsx文件,方便处理。
全部源代码如下所示:
(分号是个人习惯,不喜勿喷……)
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 |
from bs4 import BeautifulSoup
import datetime from tinydb import TinyDB, Query import urllib3 import xlsxwriter urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning); url = ‘http://hz.58.com/bijiben/0/?minprice=5000_5500’; def make_soup(url): def main(url): while url: url = False; print (“Items indexed: “,total_added); make_excel(db); def soup_process(url, db): soup = make_soup(url); for result in results: Result = Query(); if not s1: except (AttributeError, KeyError) as ex: return soup; def make_excel(db): workbook = xlsxwriter.Workbook(‘hz58.xlsx’); worksheet.set_column(0,0, 20); for col, title in enumerate(Headlines): for item in db.all(): workbook.close(); main(url); |
得到的Excel文件如下图所示。
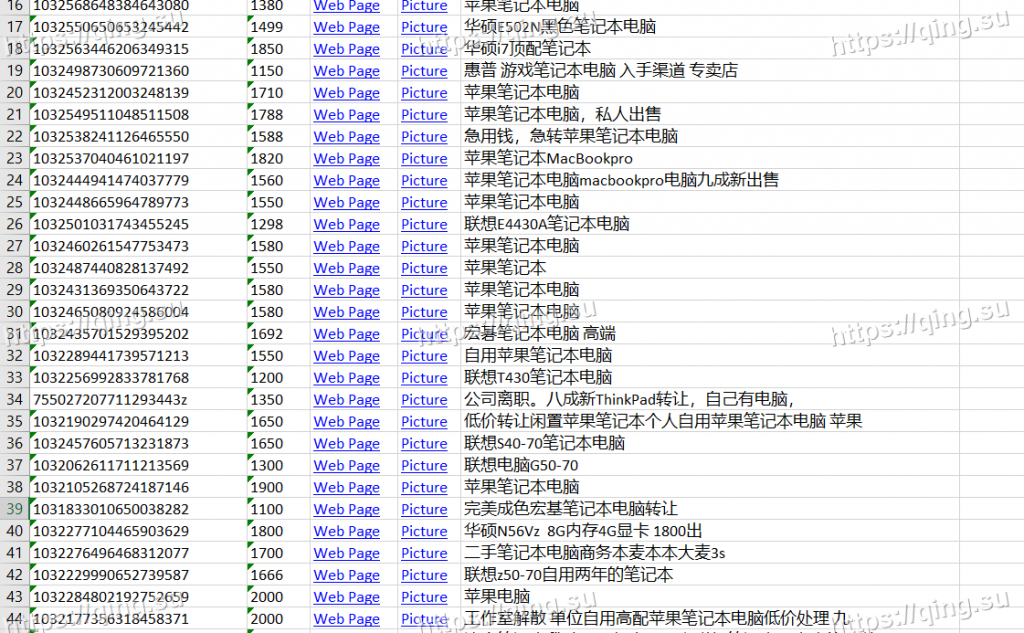
综上,我们采用Beautiful Soup, 抓取了58同城网二手电脑的部分信息。文中提到的方法可以被轻松地用来编写一系列的爬虫,实现获取网页资源。如果您有什么问题,欢迎在这里留言,我将尽力为您解答。
一、如果您发现本站侵害了相关版权,请附上本站侵权链接和您的版权证明一并发送至邮箱:yehes#qq.com(#替换为@)我们将会在五天内处理并断开该文章下载地址。
二、本站所有资源来自互联网整理收集,全部内容采用撰写共用版权协议,要求署名、非商业用途和相同方式共享,如转载请也遵循撰写共用协议。
三、根据署名-非商业性使用-相同方式共享 (by-nc-sa) 许可协议规定,只要他人在以原作品为基础创作的新作品上适用同一类型的许可协议,并且在新作品发布的显著位置,注明原作者的姓名、来源及其采用的知识共享协议,与该作品在本网站的原发地址建立链接,他人就可基于非商业目的对原作品重新编排、修改、节选或者本人的作品为基础进行创作和发布。
四、基于原作品创作的所有新作品都要适用同一类型的许可协议,因此适用该项协议, 对任何以他人原作为基础创作的作品自然同样都不得商业性用途。
五、根据二〇〇二年一月一日《计算机软件保护条例》规定:为了学习和研究软件内含的设计思想和原理,通过安装、显示、传输或者存储软件等方式使用软件的,可不经软件著作权人许可,无需向其支付报酬!
六、鉴此,也望大家按此说明转载和分享资源!本站提供的所有信息、教程、软件版权归原公司所有,仅供日常使用,不得用于任何商业用途,下载试用后请24小时内删除,因下载本站资源造成的损失,全部由使用者本人承担!



