
识别验证码
在我们的生活中,验证码是经常使用到的一个东西,那么有没有一种程序可以自动识别验证码呢?
准备步骤:生成验证码
首先我们生成一部分的验证码用以识别。
import random
from PIL import Image, ImageDraw, ImageFont
def getRandomStr():
random_num = str(random.randint(0, 9))
return random_num
def getRandomColor():
R = random.randint(0, 255)
G = random.randint(0, 255)
B = random.randint(0, 255)
if R == 255 and G == 255 and B == 255:
R = G = B = 0
return (R, G, B)
def generate_captcha():
image = Image.new('RGB', (150, 50), (255, 255, 255))
draw = ImageDraw.Draw(image)
font = ImageFont.truetype('LiberationSans-Bold.ttf', size=32)
label = ''
for i in range(5):
random_char = getRandomStr()
label += random_char
draw.text((10 + i * 30, 0), random_char, getRandomColor(), font=font)
width = 150
height = 30
for i in range(3):
x1 = random.randint(0, width)
x2 = random.randint(0, width)
y1 = random.randint(0, height)
y2 = random.randint(0, height)
draw.line((x1, y1, x2, y2), fill=(0, 0, 0))
for i in range(5):
draw.point([random.randint(0, width), random.randint(0, height)], fill=getRandomColor())
x = random.randint(0, width)
y = random.randint(0, height)
draw.arc((x, y, x + 4, y + 4), 0, 90, fill=(0, 0, 0))
image.save(open(''.join(['captcha_predict/', 'unknown.png']), 'wb'), 'png')
if __name__ == '__main__':
generate_captcha()
生成验证码的效果如下图:
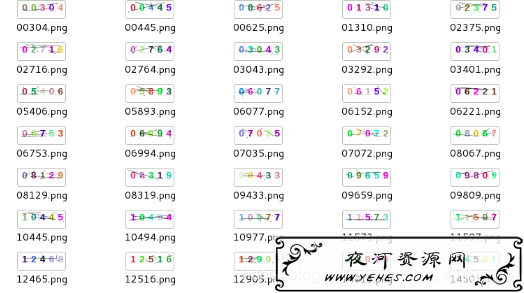
进行识别:首先对验证码进行降噪
降噪:顾名思义,降低噪音,也就是将验证码中那些无用的东西去除掉,比如一些点、线之类的
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import os
def binarization(path):
img = Image.open(path)
img_gray = img.convert('L')
img_gray = np.array(img_gray)
w, h = img_gray.shape
for x in range(w):
for y in range(h):
gray = img_gray[x, y]
if gray <= 250:
img_gray[x, y] = 0
else:
img_gray[x, y] = 1
return img_gray
def noiseReduction(img_gray, label):
width, height = img_gray.shape
for x in range(width):
for y in range(height):
count = 0
if img_gray[x, y] == 1:
continue
try:
if img_gray[x - 1, y - 1] == 0:
count += 1
except:
pass
try:
if img_gray[x - 1, y] == 0:
count += 1
except:
pass
try:
if img_gray[x - 1, y + 1] == 0:
count += 1
except:
pass
try:
if img_gray[x, y + 1] == 0:
count += 1
except:
pass
try:
if img_gray[x + 1, y + 1] == 0:
count += 1
except:
pass
try:
if img_gray[x + 1, y] == 0:
count += 1
except:
pass
try:
if img_gray[x + 1, y - 1] == 0:
count += 1
except:
pass
try:
if img_gray[x, y - 1] == 0:
count += 1
except:
pass
if count < 4:
img_gray[x, y] = 1
plt.figure('')
plt.imshow(img_gray, cmap='gray')
plt.axis('off')
plt.savefig(''.join(['降噪image/', label, '.png']))
def cutImg(label):
labels = list(label)
img = Image.open(''.join(['降噪image/', label, '.png']))
for i in range(5):
pic = img.crop((100 * (1 + i), 170, 100 * (2 + i), 280))
plt.imshow(pic)
seq = get_save_seq(label[i])
pic.save(''.join(['cut_number/', str(label[i]), '/', str(seq), '.png']))
def get_save_seq(num):
numlist = os.listdir(''.join(['cut_number/', num, '/']))
if len(numlist) == 0 or numlist is None:
return 0
else:
max_file = 0
for file in numlist:
if int(file.split('.')[0]) > max_file:
max_file = int(file.split('.')[0])
return int(max_file + 1)
if __name__ == '__main__':
img_list = os.listdir('captcha_images/')
label_list = []
for img in img_list:
img = str(img).replace('.png', '')
label_list.append(img)
for label in label_list:
img = 'captcha_images/' + label + '.png'
img_gray = binarization(img)
noiseReduction(img_gray, label)
cutImg(label)
降噪后的效果如下:
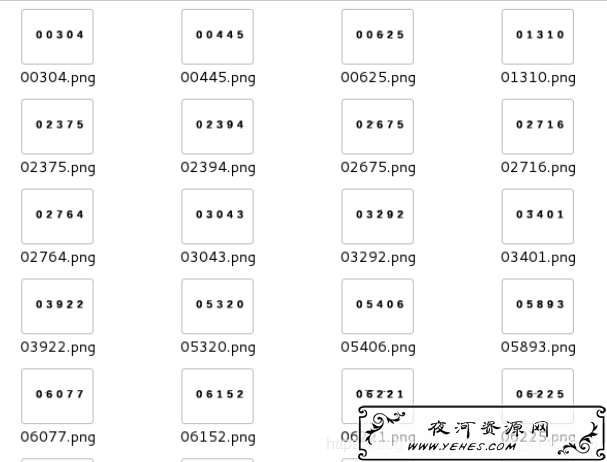
进行识别:切片建模
from sklearn.externals import joblib
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from 机器学习.降噪 import *
def load_train_data():
X = []
Y = []
cut_list = os.listdir('cut_number')
for numC in cut_list:
num_list_dir = ''.join(['cut_number/', str(numC), '/'])
nums_dir = os.listdir((num_list_dir))
for num_file in nums_dir:
img = Image.open(''.join((['cut_number/', str(numC), '/', num_file])))
img_gray = img.convert('L')
img_array = np.array(img_gray)
w, h = img_array.shape
for x in range(w):
for y in range(h):
gray = img_array[x, y]
if gray <= 250:
img_array[x, y] = 0
else:
img_array[x, y] = 1
img_re = img_array.reshape(1, -1)
X.append(img_re[0])
Y.append(int(numC))
# print(np.array(X), np.array(Y))
return np.array(X), np.array(Y)
def generate_model(X, Y):
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3)
log_clf = LogisticRegression(multi_class='ovr', solver='sag', max_iter=10000)
log_clf.fit(X_train, Y_train)
joblib.dump(log_clf, 'captcha_model/captcha_model.model')
def get_model():
model = joblib.load('captcha_model/captcha_model.model')
return model
def captcha_predict():
path = 'captcha_predict/unknown.png'
pre_img_gray = binarization(path)
noiseReduction(pre_img_gray,'unknown')
labels = ['0','1','2','3','4']
img = Image.open(''.join(['降噪image/unknown.png']))
for i in range(5):
pic = img.crop((100 * (1 + i), 170, 100 * (2 + i), 280))
plt.imshow(pic)
pic.save(''.join(['captcha_predict/',labels[i],'.png']))
result = ''
model = get_model()
for i in range(5):
path = ''.join(['captcha_predict/',labels[i],'.png'])
img = Image.open(path)
img_gray = img.convert('L')
img_array = np.array(img_gray)
w, h = img_array.shape
for x in range(w):
for y in range(h):
gray = img_array[x, y]
if gray <= 250:
img_array[x, y] = 0
else:
img_array[x, y] = 1
img_re = img_array.reshape(1.-1)
X = img_re[0]
Y_pre = model.predict([X])
result = ''.join([result,str(Y_pre[0])])
return result
if __name__ == '__main__':
X,Y=load_train_data()
generate_model(X,Y)
# print(captcha_predict())
切片效果如下
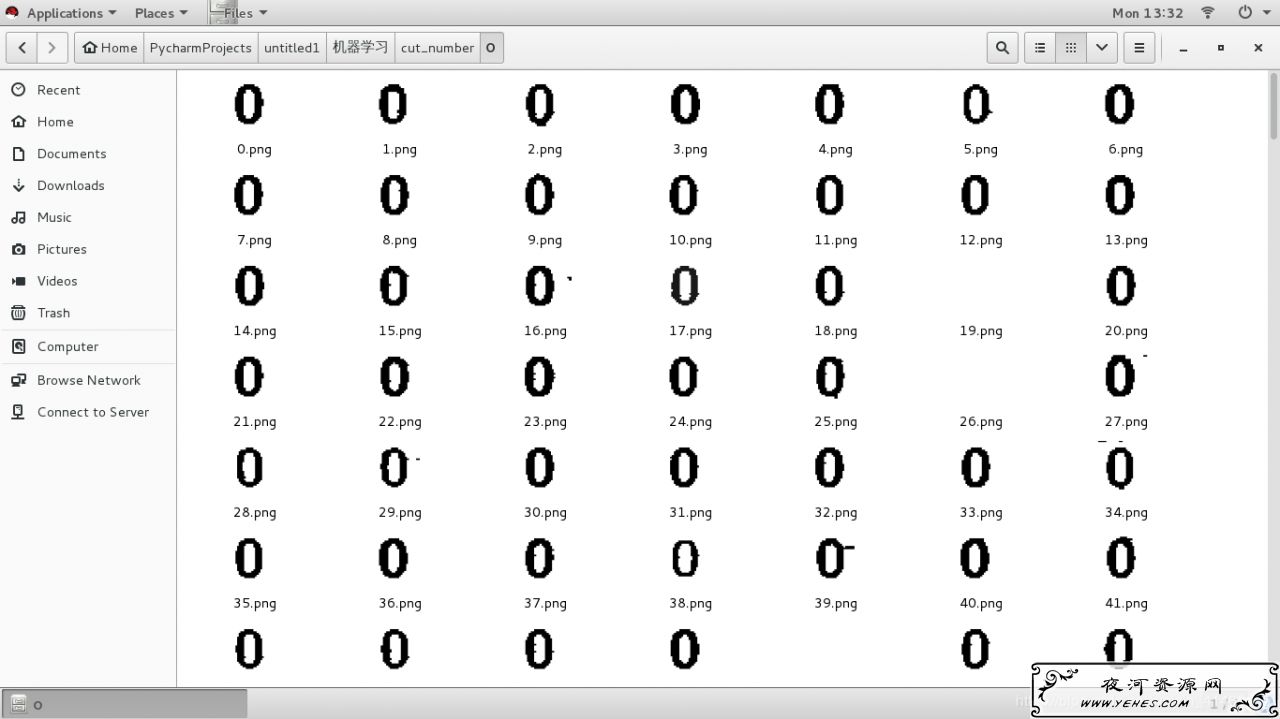
夜河资源网提供的所有内容仅供学习与交流。通过使用本站内容随之而来的风险以及法律责任与本站无关,所承担的法律责任由使用者承担。
一、如果您发现本站侵害了相关版权,请附上本站侵权链接和您的版权证明一并发送至邮箱:yehes#qq.com(#替换为@)我们将会在五天内处理并断开该文章下载地址。
二、本站所有资源来自互联网整理收集,全部内容采用撰写共用版权协议,要求署名、非商业用途和相同方式共享,如转载请也遵循撰写共用协议。
三、根据署名-非商业性使用-相同方式共享 (by-nc-sa) 许可协议规定,只要他人在以原作品为基础创作的新作品上适用同一类型的许可协议,并且在新作品发布的显著位置,注明原作者的姓名、来源及其采用的知识共享协议,与该作品在本网站的原发地址建立链接,他人就可基于非商业目的对原作品重新编排、修改、节选或者本人的作品为基础进行创作和发布。
四、基于原作品创作的所有新作品都要适用同一类型的许可协议,因此适用该项协议, 对任何以他人原作为基础创作的作品自然同样都不得商业性用途。
五、根据二〇〇二年一月一日《计算机软件保护条例》规定:为了学习和研究软件内含的设计思想和原理,通过安装、显示、传输或者存储软件等方式使用软件的,可不经软件著作权人许可,无需向其支付报酬!
六、鉴此,也望大家按此说明转载和分享资源!本站提供的所有信息、教程、软件版权归原公司所有,仅供日常使用,不得用于任何商业用途,下载试用后请24小时内删除,因下载本站资源造成的损失,全部由使用者本人承担!
一、如果您发现本站侵害了相关版权,请附上本站侵权链接和您的版权证明一并发送至邮箱:yehes#qq.com(#替换为@)我们将会在五天内处理并断开该文章下载地址。
二、本站所有资源来自互联网整理收集,全部内容采用撰写共用版权协议,要求署名、非商业用途和相同方式共享,如转载请也遵循撰写共用协议。
三、根据署名-非商业性使用-相同方式共享 (by-nc-sa) 许可协议规定,只要他人在以原作品为基础创作的新作品上适用同一类型的许可协议,并且在新作品发布的显著位置,注明原作者的姓名、来源及其采用的知识共享协议,与该作品在本网站的原发地址建立链接,他人就可基于非商业目的对原作品重新编排、修改、节选或者本人的作品为基础进行创作和发布。
四、基于原作品创作的所有新作品都要适用同一类型的许可协议,因此适用该项协议, 对任何以他人原作为基础创作的作品自然同样都不得商业性用途。
五、根据二〇〇二年一月一日《计算机软件保护条例》规定:为了学习和研究软件内含的设计思想和原理,通过安装、显示、传输或者存储软件等方式使用软件的,可不经软件著作权人许可,无需向其支付报酬!
六、鉴此,也望大家按此说明转载和分享资源!本站提供的所有信息、教程、软件版权归原公司所有,仅供日常使用,不得用于任何商业用途,下载试用后请24小时内删除,因下载本站资源造成的损失,全部由使用者本人承担!



