
转载自:https://www.taterli.com/
第一步,爬取并入库MySQL,这一步占了最多的时间,为了避免被Anti-Spider机制影响,所以限速也较低.

因为URL格式里面似乎包含了ID信息,所以也一并采集了.

第一段ID似乎是小说ID,第二段ID似乎是章节ID,章节ID和小说ID并非连续,但是同样的小说ID下,章节ID必然递增存在,所以储存时候就这么干.(正文内容省略)
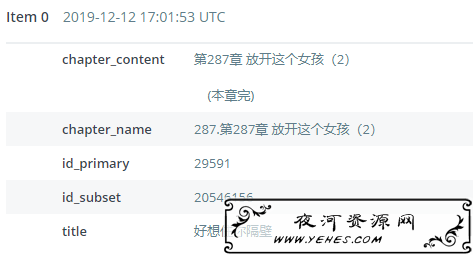
第二步就是得到CSV文件(大约100GB),然后从CSV文件入库,为什么不用pipeline入库的原因是数据库是临时用的,按需付费省着用.
CREATE DATABASE `books` use books; DROP TABLE `scrapy`; CREATE TABLE `scrapy` ( `id` INT NOT NULL AUTO_INCREMENT, `id_primary` INT NOT NULL, `id_subset` INT NOT NULL, `title` VARCHAR(200) NOT NULL DEFAULT '', `chapter_name` VARCHAR(200) NOT NULL DEFAULT '', `chapter_content` MEDIUMTEXT, `created_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP(), PRIMARY KEY (`id`), INDEX `id_subset` (`id_subset`), INDEX `id_primary` (`id_primary`) )ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; LOAD DATA LOCAL INFILE '/mnt/ScrapyBooks.csv' IGNORE INTO TABLE scrapy CHARACTER SET utf8mb4 FIELDS TERMINATED BY ',' LINES TERMINATED BY 'rn' IGNORE 1 LINES (`chapter_content`,`chapter_name`,`id_primary`,`id_subset`,`title`); SHOW WARNINGS;
如果采集到的CSV 100G的话,入库大概需要170G的数据库空间,另外CSV文件需要处理,否则会被意外截断,前面已经有文章说过.
导入成功的最佳结果当然是0错误,0警告了.

第三步就是从数据库再提取回来,生成TXT文本的小说,当然,都入库了也可以用来生成网站.
import pymysql def make( id ): cursor = db.cursor() sql = "SELECT * FROM scrapy WHERE id_primary = " str(id) " ORDER BY id_subset ASC" cursor.execute(sql) result = cursor.fetchone() if result[3] == "": print('似乎出现了书名不正确的情况') print(result) return print('正在写入 ' result[3] '.txt') wf = open('/mnt/volume_fra1_02/books/' result[3] '.txt','a') #至少先做第一次提取,写入标题,然后检测标题是否在正文有重复,如果有重复,删除正文标题. wf.write(result[4] 'rn') content = result[5].replace(result[4],'') wf.write(content.strip('"') 'rn' 'rn') while result is not None: result = cursor.fetchone() if result is not None: wf.write(result[4] 'rn') content = result[5].replace(result[4],'') wf.write(content.strip('"') 'rn' 'rn') wf.close() db = pymysql.connect(host="127.0.0.1",user="root",db="books",cursorclass = pymysql.cursors.SSCursor) cursor = db.cursor() sql = "SELECT DISTINCT id_primary FROM scrapy" cursor.execute(sql) id_dict = [] result = cursor.fetchone() id_dict.append(result[0]) while result is not None: result = cursor.fetchone() if result is not None: id_dict.append(result[0]) for tid in id_dict: make(tid) cursor.close() db.close()
写入数据中…
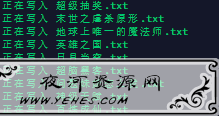
打开检查,发现顺序正确,内容没问题.
第四步,导出的文件总量大小约等于CSV文件大小(可能略大/略小),有些只有几MB,有些几十上百M,抽查发现有些提取出现问题,这个也是因为蜘蛛算法问题,看起来需要一些容错机制才行.
BUG举例:
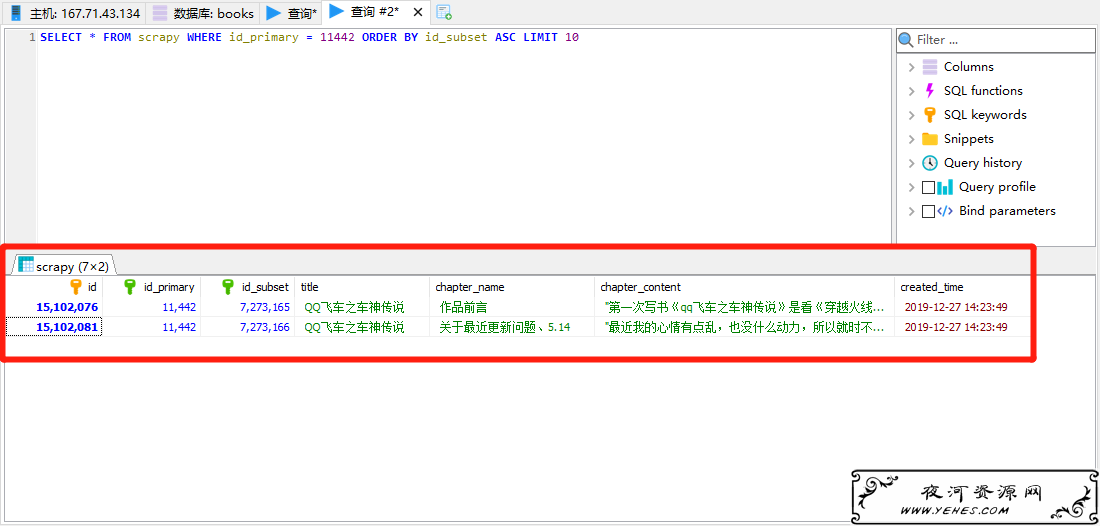
导致原因,我用的XPATH提取了第一个ul,但是有些地方目录在第二个ul,所以出错了.
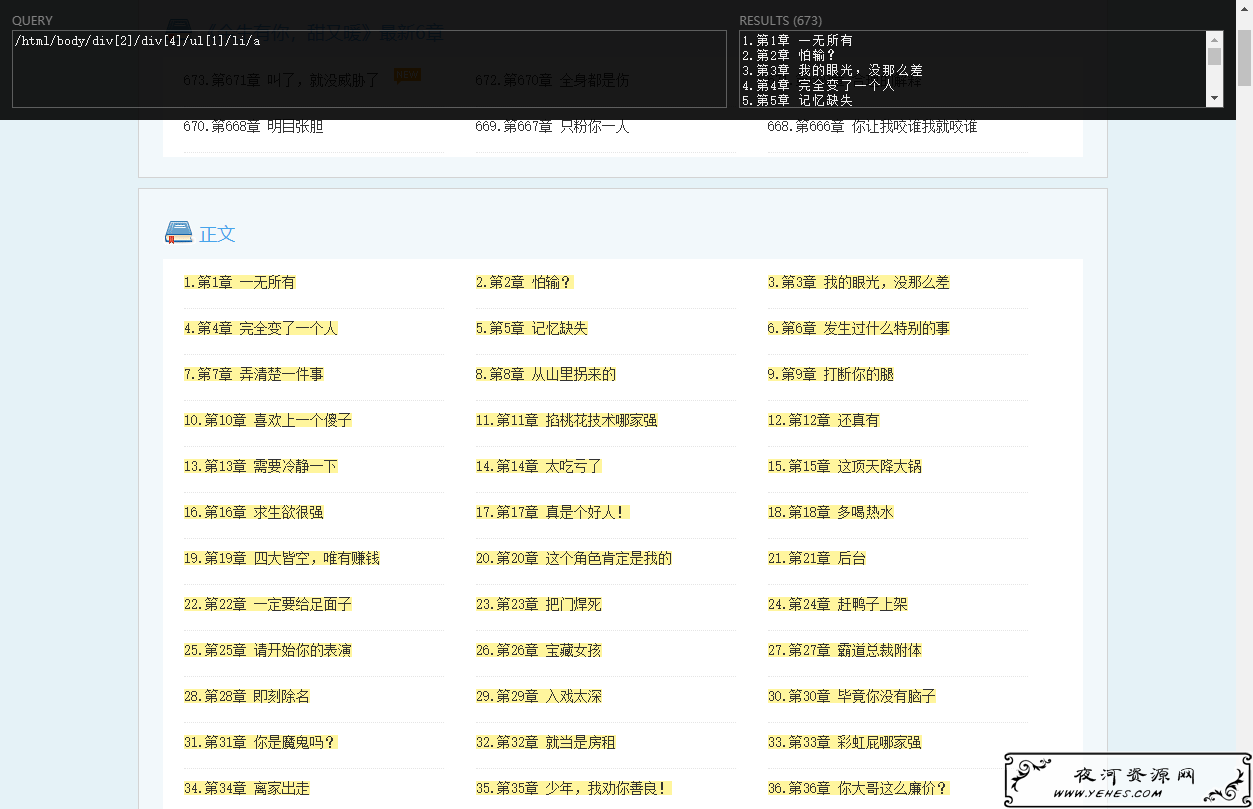
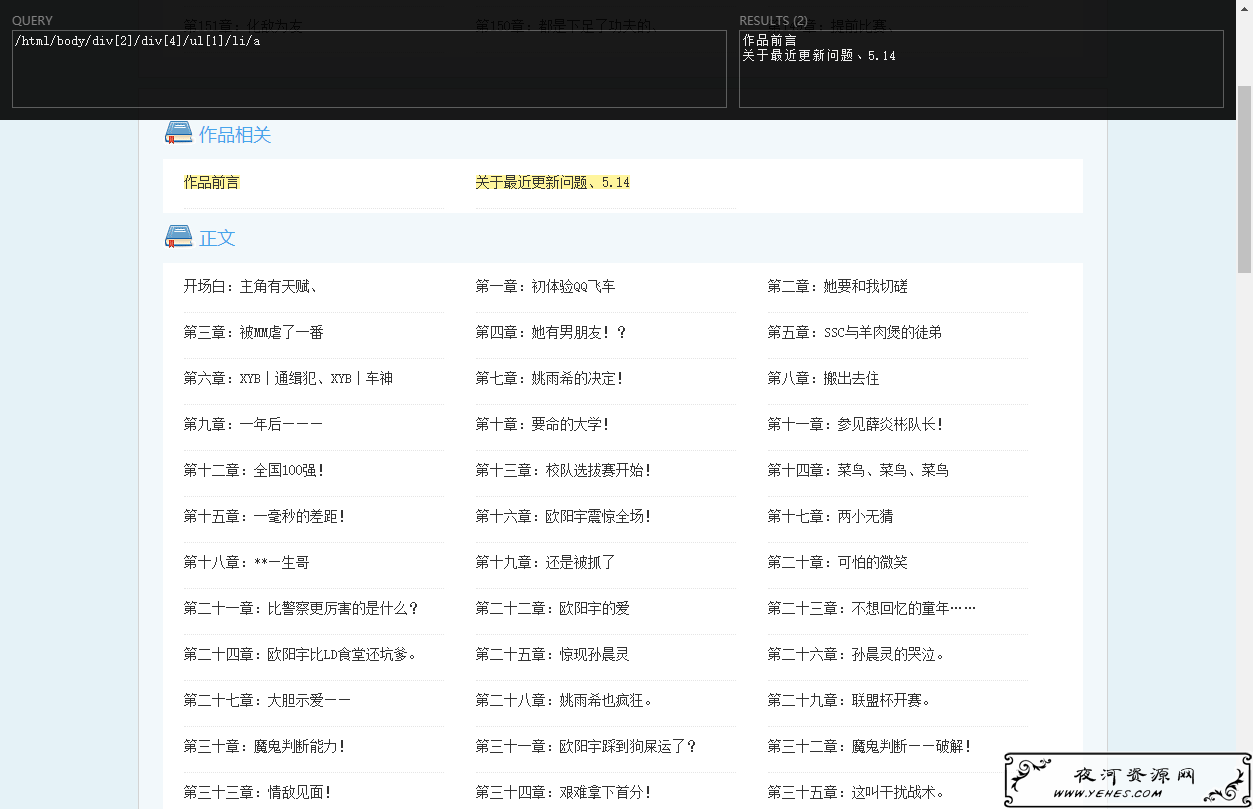
第一代含BUG爬虫先结束他,想搞第二代时候再说吧.
夜河资源网提供的所有内容仅供学习与交流。通过使用本站内容随之而来的风险以及法律责任与本站无关,所承担的法律责任由使用者承担。
一、如果您发现本站侵害了相关版权,请附上本站侵权链接和您的版权证明一并发送至邮箱:yehes#qq.com(#替换为@)我们将会在五天内处理并断开该文章下载地址。
二、本站所有资源来自互联网整理收集,全部内容采用撰写共用版权协议,要求署名、非商业用途和相同方式共享,如转载请也遵循撰写共用协议。
三、根据署名-非商业性使用-相同方式共享 (by-nc-sa) 许可协议规定,只要他人在以原作品为基础创作的新作品上适用同一类型的许可协议,并且在新作品发布的显著位置,注明原作者的姓名、来源及其采用的知识共享协议,与该作品在本网站的原发地址建立链接,他人就可基于非商业目的对原作品重新编排、修改、节选或者本人的作品为基础进行创作和发布。
四、基于原作品创作的所有新作品都要适用同一类型的许可协议,因此适用该项协议, 对任何以他人原作为基础创作的作品自然同样都不得商业性用途。
五、根据二〇〇二年一月一日《计算机软件保护条例》规定:为了学习和研究软件内含的设计思想和原理,通过安装、显示、传输或者存储软件等方式使用软件的,可不经软件著作权人许可,无需向其支付报酬!
六、鉴此,也望大家按此说明转载和分享资源!本站提供的所有信息、教程、软件版权归原公司所有,仅供日常使用,不得用于任何商业用途,下载试用后请24小时内删除,因下载本站资源造成的损失,全部由使用者本人承担!
一、如果您发现本站侵害了相关版权,请附上本站侵权链接和您的版权证明一并发送至邮箱:yehes#qq.com(#替换为@)我们将会在五天内处理并断开该文章下载地址。
二、本站所有资源来自互联网整理收集,全部内容采用撰写共用版权协议,要求署名、非商业用途和相同方式共享,如转载请也遵循撰写共用协议。
三、根据署名-非商业性使用-相同方式共享 (by-nc-sa) 许可协议规定,只要他人在以原作品为基础创作的新作品上适用同一类型的许可协议,并且在新作品发布的显著位置,注明原作者的姓名、来源及其采用的知识共享协议,与该作品在本网站的原发地址建立链接,他人就可基于非商业目的对原作品重新编排、修改、节选或者本人的作品为基础进行创作和发布。
四、基于原作品创作的所有新作品都要适用同一类型的许可协议,因此适用该项协议, 对任何以他人原作为基础创作的作品自然同样都不得商业性用途。
五、根据二〇〇二年一月一日《计算机软件保护条例》规定:为了学习和研究软件内含的设计思想和原理,通过安装、显示、传输或者存储软件等方式使用软件的,可不经软件著作权人许可,无需向其支付报酬!
六、鉴此,也望大家按此说明转载和分享资源!本站提供的所有信息、教程、软件版权归原公司所有,仅供日常使用,不得用于任何商业用途,下载试用后请24小时内删除,因下载本站资源造成的损失,全部由使用者本人承担!



